What is Serverless
Traditionally, we’ve built and deployed web applications where we have some degree of control over the HTTP requests that are made to our server. Our application runs on that server and we are responsible for provisioning and managing the resources for it. There are a few issues with this.
-
We are charged for keeping the server up even when we are not serving out any requests.
-
We are responsible for uptime and maintenance of the server and all its resources.
-
We are also responsible for applying the appropriate security updates to the server.
-
As our usage scales we need to manage scaling up our server as well. And as a result manage scaling it down when we don’t have as much usage.
For smaller companies and individual developers this can be a lot to handle. This ends up distracting from the more important job that we have; building and maintaining the actual application. At larger organisations this is handled by the infrastructure team and usually it is not the responsibility of the individual developer. However, the processes necessary to support this can end up slowing down development times. As you cannot just go ahead and build your application without working with the infrastructure team to help you get up and running.
As developers we’ve been looking for a solution to these problems and this is where serverless comes in. Serverless allows us to build applications where we simply hand the cloud provider (AWS, Azure, or Google Cloud) our code and it runs it for us. It also allocates the appropriate amount of resources to respond to the usage. On our end we only get charged for the time it took our code to execute and the resources it consumed. If we are undergoing a spike of usage, the cloud provider simply creates more instances of our code to respond to the requests. Additionally, our code runs in a secured environment where the cloud provider takes care of keeping the server up to date and secure.
AWS Lambda
In serverless applications we are not responsible for handling the requests that come in to our server. Instead the cloud provider handles the requests and sends us an object that contains the relevant info and asks us how we want to respond to it. The request is treated as an event and our code is simply a function that takes this as the input. As a result we are writing functions that are meant to respond to these events. So when a user makes a request, the cloud provider creates a container and runs our function inside it. If there are two concurrent requests, then two separate containers are created to respond to the requests.
In the AWS world the serverless function is called AWS Lambda and our serverless backend is simply a collection of Lambdas. Here is what a Lambda function looks like.
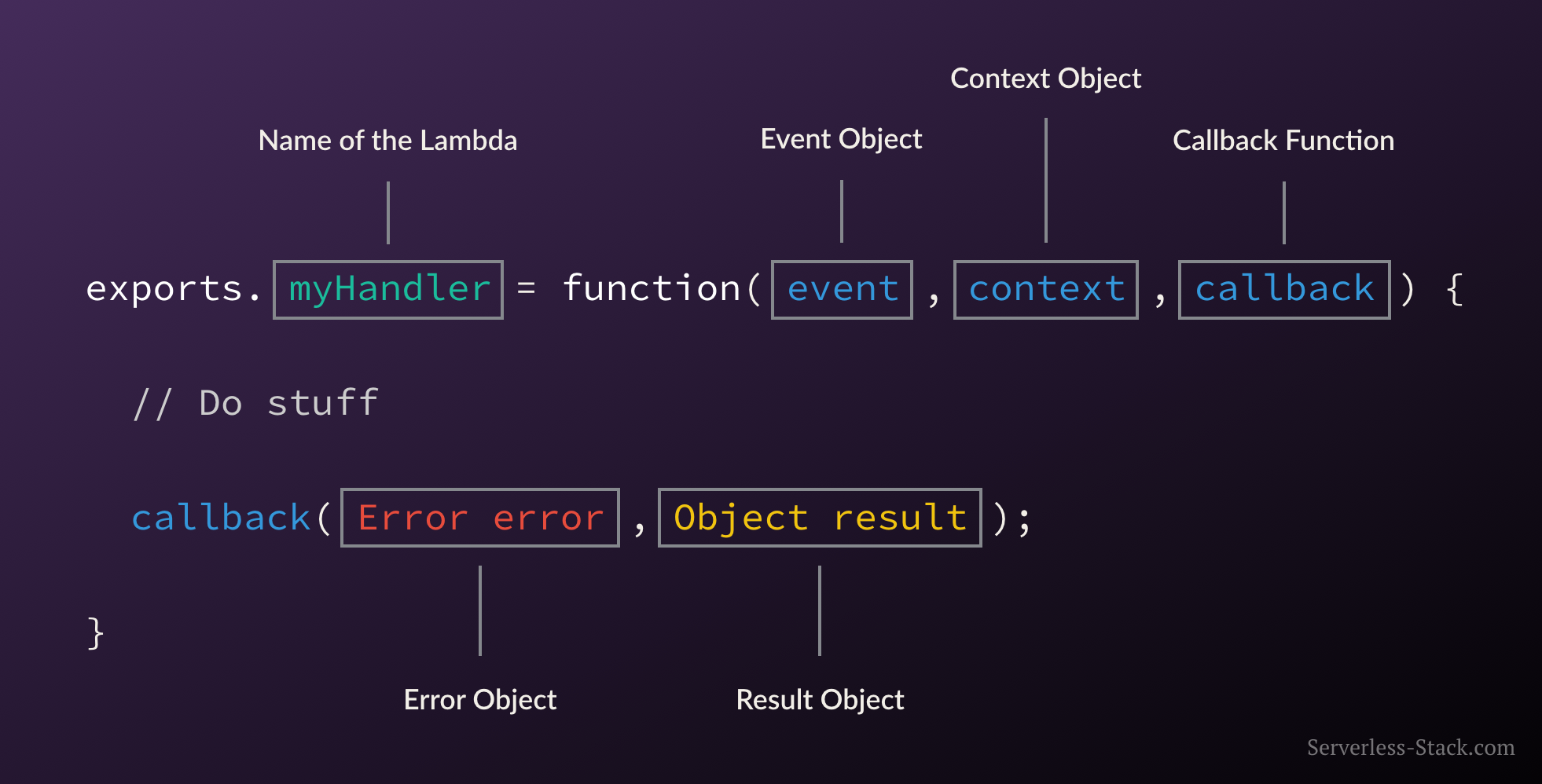
Here myHandler is the name of our Lambda function. The event object contains all the information about the event that triggered this Lambda. In our case it’ll be information about the HTTP request. The context object contains info about the runtime our Lambda function is executing in. After we do all the work inside our Lambda function, we simply call the callback function with the results (or the error) and AWS will respond to the HTTP request with it.
While this example is in JavaScript (or Node.js), AWS Lambda supports Python, Java, and C# as well. Lambda functions are charged for every 100ms that it uses and as mentioned above they automatically scale to respond to the usage. The Lambda runtime also comes with 512MB of ephemeral disk space and up to 3008MB of memory.
Next, let’s take a deeper look into the advantages of serverless including the cost of running our demo app.

If you liked this post, please subscribe to our newsletter, give us a star on GitHub, and check out our sponsors.
For help and discussion
Comments on this chapter